NLP Theory and Code: Encoder-Decoder Models (Part 11/30)
Sequence to Sequence Network, Contextual Representation

Introduction..
In tasks like machine translation, we must map from a sequence of input words to a sequence of output words. The reader must note that this is not similar to “sequence labelling”, where that task it to to map each word in the sequence to a predefined classes, like part-of-speech or named entity task.

In above two examples, the models are tasked to map each word in the sequence to a tag/class.

But in tasks like machine translation: the length of inputs sequence need to not necessarily length of output sequence. As you can see in the google translation example, the input length is “5” and output length is “4”. Since we are mapping an input sequence to an output sequence, thus comes the name sequence to sequence models. Not only the length of input and output sequence differs but the order of words also differ. This is very complex task in NLP and Encoder- decoder networks are very successful at handling these sorts of complicated tasks of sequence to sequence mapping.
One more important task that can be solved with encoder-decoder networks is text summarisation where we map the long text to a short summary/abstract. In this blog we will try to understand the architecture of encoder-decoder networks and how it works.
The Encoder-Decoder Network..
This network have been applied to very wide range of applications including machine translation, text summarisation, questioning answering and dialogue. Let’s try to understand the idea underlying the encoder-decoder networks. The encoder takes the input sequence and creates a contextual representation (which is also called context) of it and the decoder takes this contextual representation as input and generates output sequence.

Encoder and Decoder with RNN’s…
All variants of RNN’s can be employed as encoders and decoders . In RNN’s we have notion of hidden state “ht” which can be seen as a summary of words/tokens it has seen till time step “t” in the sequence chain.
Encoder:
Encoder takes the input sequence and generated a context which is the essence of the input to the decoder.

The entire purpose of the encoder is to generate a contextual representation/ context for the input sequence. Using RNN as encoder, the final hidden state of the RNN sequence chain can be used a proxy for context. This is the most critical concept which forms the basis for encoder-decoder models. We will use the subscripts e and d for the hidden state of the encoder and decoder. Outputs of encoder is ignored, as the goal is to generate final hidden state or context for decoder.
Decoder:
Decoder takes the context as input and generates a sequence of output. When we employ RNN as decoder, the context is the final hidden state of the RNN encoder.
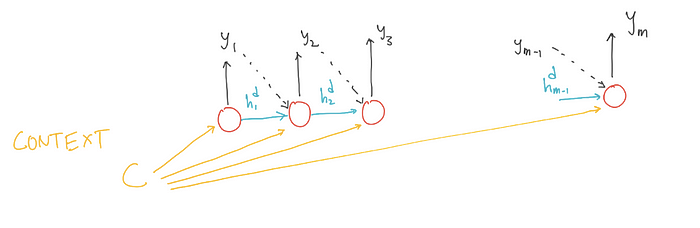
The first decoder RNN cell takes “CONTEXT” as its prior hidden state. The decoder then generated the output until the end-of-sequence marker is generated.
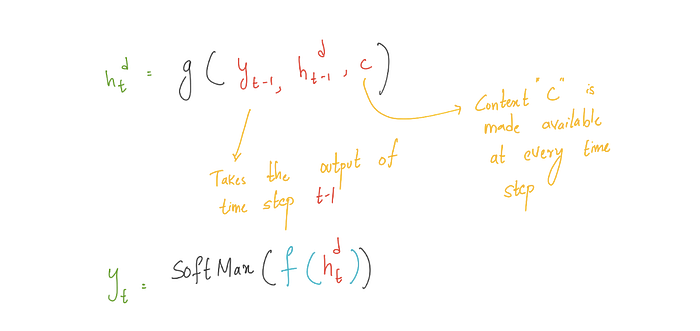
Each cell in RNN decoder takes input auto regressively, i.e, The decoder uses its own estimated output at time t as the input for the next time step xt+1. One important drawback if the context is made available only for first decoder RNN cell is the the context wanes as more and more output sequence is generated. To overcome this drawback the “CONTEXT” can be made available at each decoding RNN time step. There is a little deviation from the vanilla-RNN. Let’s look at the updated the equations for decoder RNN.
Training the Encoder — Decoder Model..
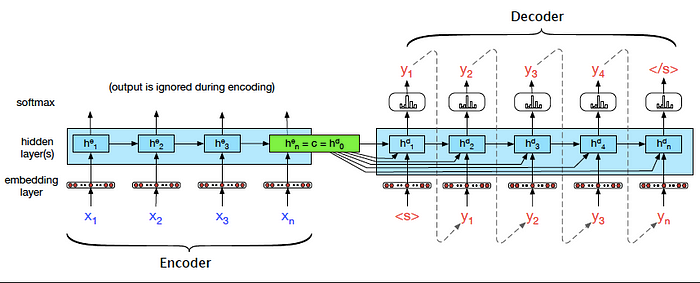
The training data consists of sets of input sentences and their respective output sequences . We use cross entropy loss in the decoder. Encoder-decoder architectures are trained end-to-end, just as with the RNN language models. The loss is calculated and then back-propogated to update weights using the gradient descent optimisation. The total loss is calculated by averaging the cross-entropy loss per target word.
Note..
Linguistic typology: It is a concept pertinent to machine translation. The languages differ in many ways. The study of these systematic differences and cross linguistic similarities is called linguistic typology.
Lexical Gap: It is a concept pertinent to machine translation. In a given language, there might not be a word or phrase that can express the exact meaning of a word in other language.

Previous: NLP Zero to One: Bi-Directional LSTM Part(10/30)
Next:NLP Zero to One: Attention Mechanism (Part 12/30)

