PinnedKowshik chilamkurthyinDataDrivenInvestorP-DQN: An Unique Algorithm for Discrete-Continuous Hybrid Action SpaceParameterised Deep Q Learning5 min read·Jan 12, 2022--1--1
Kowshik chilamkurthyReinforcement Learning for Optimal Station PolicyProblem Statement4 min read·Oct 24, 2022----
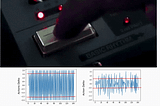
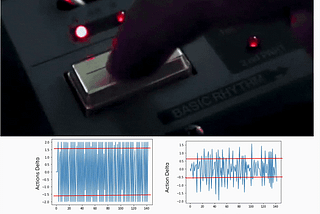
Kowshik chilamkurthyinDataDrivenInvestorHold Your Horses, My Dear Reinforcement Learning AgentStopping RL Agent From Taking Erratic Action Jumps4 min read·Sep 12, 2022--1--1
Kowshik chilamkurthyinAnalytics Vidhya(1/2) Same Story(MLE) Different Endings: Mean Square Error, Cross Entropy, KL DivergenceMathematically Proving That They are All the Same5 min read·Aug 1, 2022--1--1
Kowshik chilamkurthyinThe Enlightened IndianHow Caste System Born and Functions In India — Part — 1Penning my understanding from the writings of Dr.B.R Ambedkar4 min read·Jan 30, 2022----
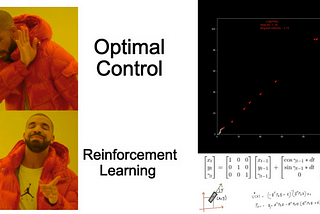
Kowshik chilamkurthyRL vs Optimal Control: LQR for Trajectory Tracking (With Python Code)The Linear Quadratic Regulator6 min read·Nov 4, 2021--1--1
Kowshik chilamkurthyinAnalytics VidhyaImitate with Caution: Offline and Online ImitationBehavioural Cloning, Data Aggregation Approach: DAGGER.5 min read·Oct 6, 2021----
Kowshik chilamkurthyinNerd For TechA Unique Intersection of Game Theory and Data Science: E-Commerce Product PricingPrice Elasticity, Cross Elasticity and Nash Equilibrium9 min read·Jun 18, 2021----
Kowshik chilamkurthyinNerd For TechQuick Game Theory Blog Series For Dummies6 -blog series Each less than 5 Minutes1 min read·May 29, 2021----
Kowshik chilamkurthyinNerd For TechGame Theory: Nash Equilibrium For Mixed Strategies ( Part 6 )Continuous actions and Stochastic Strategic Games6 min read·May 29, 2021----